به دلیل فقدان رقابت غنی، برخی از مهمترین نتایج انویدیا در آخرین MLPerf علیه خودش بود و جدیدترین GPU آن، H100 “Hopper” را با محصول موجود خود، A100 مقایسه کرد. Nvidia
اگرچه غول تراشههای انویدیا سایهای طولانی بر دنیای هوش مصنوعی افکنده است، اما اگر آخرین نتایج تست معیار نشاندهنده باشد، توانایی آن برای بیرون راندن رقابت از بازار ممکن است در حال افزایش باشد.
MLCommons، کنسرسیوم صنعتی که بر تست محبوب عملکرد یادگیری ماشین، MLPerf نظارت می کند، روز چهارشنبه آخرین اعداد را برای “آموزش” شبکه های عصبی مصنوعی منتشر کرد. این آزمایش کمترین تعداد رقیب انویدیا را در سه سال اخیر نشان داد، فقط یک رقیب: غول CPU اینتل.
در دورهای گذشته، از جمله جدیدترین، در ژوئن، انویدیا دو یا چند رقیب داشت، از جمله اینتل، گوگل، با «واحد پردازش تنسور» یا TPU، تراشه و تراشههای استارتآپ بریتانیایی Graphcore. و در دورهای گذشته، غول مخابراتی چین هوآوی.
همچنین: گوگل و انویدیا رتبه های برتر را در معیار آموزشی MLPerf AI تقسیم کردند
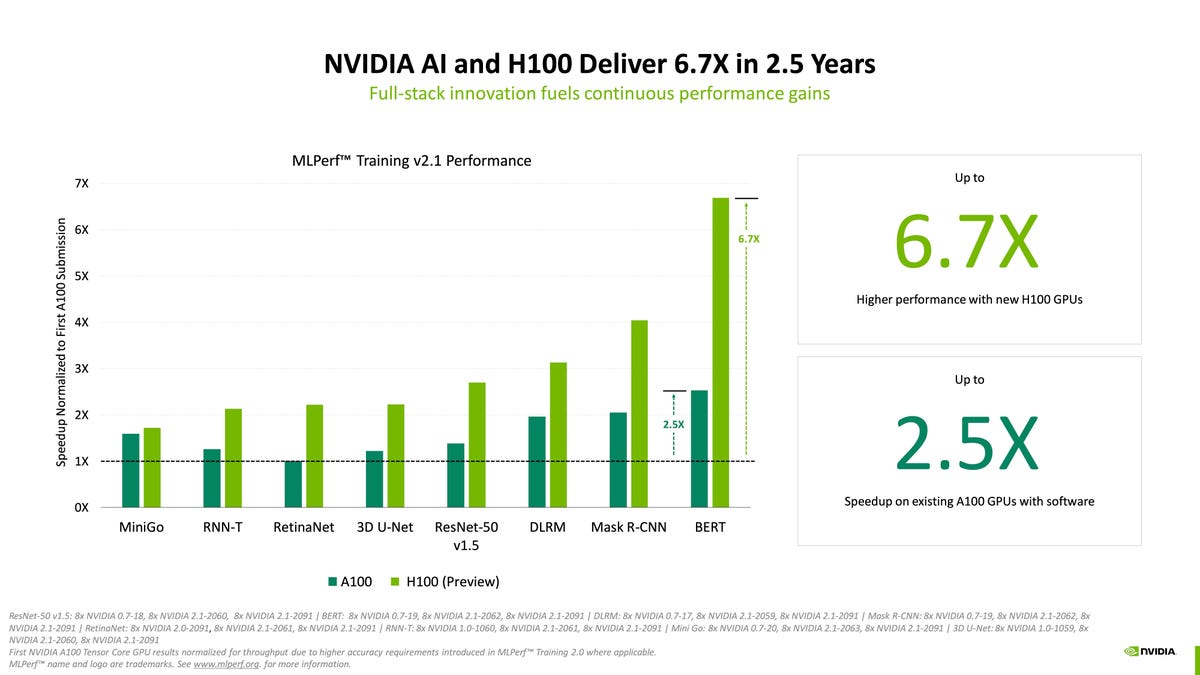
به دلیل عدم وجود رقابت، انویدیا این بار تمام امتیازات برتر را به خود اختصاص داد، در حالی که در ماه ژوئن، این شرکت رتبه برتر را با گوگل به اشتراک گذاشت. انویدیا سیستمهایی را با استفاده از پردازنده گرافیکی A100 خود که چندین سال است عرضه شده است و همچنین H100 جدید خود که به عنوان «Hopper» GPU شناخته میشود، به افتخار پیشگام محاسباتی Grace Hopper ارسال کرد. H100 در یکی از هشت تست معیار، برای سیستمهای به اصطلاح توصیهای که معمولاً برای پیشنهاد محصولات به افراد در وب استفاده میشوند، امتیاز برتر را گرفت.
اینتل دو سیستم را با استفاده از تراشههای Habana Gaudi2 و همچنین سیستمهایی با برچسب “پیش نمایش” ارائه کرد که تراشه سرور Xeon آینده خود را با نام رمز “Sapphire Rapids” نشان میداد.
سیستم های اینتل بسیار کندتر از قطعات Nvidia بودند.
Nvidia در یک بیانیه مطبوعاتی گفت: “GPU های H100 (معروف به هاپر) مدل های آموزشی را در هر هشت بار کاری سازمانی MLPerf به ثبت رساندند. آنها در اولین باری که در آموزش MLPerf ارائه شدند تا 6.7 برابر عملکرد بیشتری نسبت به GPU های نسل قبلی ارائه کردند. همان مقایسه، پردازندههای گرافیکی A100 امروزی به لطف پیشرفتهای نرمافزاری، 2.5 برابر عضله بیشتری دارند.
طی یک کنفرانس مطبوعاتی رسمی، دیو سالواتور، مدیر ارشد محصول انویدیا برای هوش مصنوعی و ابر، بر بهبود عملکرد Hopper و بهینهسازی نرمافزار در A100 تمرکز کرد. سالواتوره نشان داد که چگونه هاپر عملکرد را نسبت به A100 افزایش می دهد – به عبارت دیگر آزمایشی از انویدیا در برابر انویدیا – و همچنین نشان داد که چگونه هاپر می تواند تراشه های Gaudi2 اینتل و Sapphire Rapids را زیر پا بگذارد.
همچنین: Graphcore رقابت جدیدی را برای Nvidia در آخرین بنچمارکهای MLPerf AI به ارمغان میآورد
با توجه به اینکه در دورهای گذشته MLPerf، فروشندگان منفرد تصمیم گرفته اند از رقابت صرف نظر کنند تا در دور بعدی بازگردند، به خودی خود نشان دهنده روندی نیست.
گوگل به درخواست ZDNET برای اظهار نظر در مورد اینکه چرا این بار شرکت نکرد پاسخ نداد.
در ایمیلی، Graphcore به ZDNET گفت که تصمیم گرفته است در حال حاضر مکانهای بهتری برای اختصاص زمان مهندسان خود نسبت به هفتهها یا ماههایی که برای آمادهسازی ارسالها برای MLPerf طول میکشد داشته باشد.
ایین مککنزی، رئیس ارتباطات Graphcore، از طریق ایمیل به ZDNET گفت: «مساله کاهش بازدهی مطرح شد، به این معنا که یک جهش اجتنابناپذیر تا بینهایت وجود خواهد داشت، چند ثانیه دیگر اصلاح میشود، و پیکربندیهای سیستم همیشه بزرگتر ارائه میشوند. “
McKenzie به ZDNET گفت: Graphcore “ممکن است در دورهای آینده MLPerf شرکت کند، اما در حال حاضر حوزههایی از هوش مصنوعی را که ما در آن شاهد هیجانانگیزترین پیشرفتها هستیم، منعکس نمیکند.” وظایف MLPerf صرفاً “مشخصات جدول” هستند.
در عوض، او گفت: «ما واقعاً میخواهیم انرژی خود را بر روی «باز کردن قابلیتهای جدید برای متخصصان هوش مصنوعی» متمرکز کنیم. مک کنزی گفت: برای این منظور، “شما می توانید انتظار داشته باشید به زودی پیشرفت های هیجان انگیزی را از Graphcore مشاهده کنید”، “به عنوان مثال در مدل ها و همچنین GNN ها” یا شبکه های عصبی نمودار.
همچنین: جنسن هوانگ، مدیر عامل انویدیا، از در دسترس بودن پردازنده گرافیکی «Hopper»، سرویس ابری برای مدلهای بزرگ زبان هوش مصنوعی خبر داد.
علاوه بر چیپهای انویدیا که بر رقابت تسلط داشتند، تمام سیستمهای رایانهای که امتیازات برتر را کسب کردند، توسط انویدیا ساخته شدهاند و نه توسط شرکا. این نیز تغییری نسبت به دورهای گذشته آزمون معیار است. معمولاً برخی از فروشندگان مانند Dell برای سیستم هایی که با استفاده از تراشه های Nvidia کنار هم قرار می دهند، امتیازهای بالایی کسب می کنند. این بار، هیچ فروشنده سیستمی نتوانست انویدیا را در استفاده خود انویدیا از تراشه هایش شکست دهد.
تستهای معیار آموزشی MLPerf گزارش میدهند که چند دقیقه طول میکشد تا “وزنها” یا پارامترهای عصبی تنظیم شود، تا زمانی که برنامه کامپیوتری به حداقل دقت مورد نیاز در یک کار معین دست یابد، فرآیندی که به آن “آموزش” یک شبکه عصبی گفته میشود، که در آن زمان کوتاهتر بهتر است
اگرچه نمرات برتر اغلب سرفصلها را به خود اختصاص میدهند – و توسط فروشندگان مورد تاکید مطبوعات قرار میگیرند – در واقعیت، نتایج MLPerf شامل طیف گستردهای از سیستمها و طیف گستردهای از نمرات است، نه فقط یک امتیاز برتر.
در یک مکالمه تلفنی، مدیر اجرایی MLCommons، دیوید کانتر، به ZDNET گفت که فقط روی امتیازات برتر تمرکز نکند. کانتر گفت، ارزش مجموعه معیار برای شرکتهایی که خرید سختافزار هوش مصنوعی را ارزیابی میکنند، داشتن مجموعه گستردهای از سیستمها در اندازههای مختلف با انواع مختلف عملکرد است.
موارد ارسالی که تعدادشان به صدها میرسد، از ماشینهایی با تنها چند ریزپردازنده معمولی تا ماشینهایی که دارای هزاران پردازنده میزبان از AMD و هزاران پردازنده گرافیکی Nvidia هستند، از نوع سیستمهایی هستند که امتیازات برتر را کسب میکنند.
کانتر به ZDNET گفت: «وقتی صحبت از آموزش و استنباط ML می شود، نیازهای متنوعی برای همه سطوح مختلف عملکرد وجود دارد، و بخشی از هدف ارائه معیارهای عملکرد است که بتوان در همه آن مقیاس های مختلف استفاده کرد. “
کانتر می گوید: «اطلاعات مربوط به برخی از سیستم های کوچکتر به اندازه سیستم های مقیاس بزرگتر ارزش دارد. “همه این سیستم ها به یک اندازه مرتبط و مهم هستند، اما شاید برای افراد مختلف.”
همچنین: تست معیار عملکرد هوش مصنوعی، MLPerf، همچنان طرفداران خود را به دست می آورد
در مورد عدم مشارکت Graphcore و Google این بار، کانتر گفت: “من خیلی دوست دارم ارسال های بیشتری را ببینم” و افزود: “برای بسیاری از شرکت ها درک می کنم، آنها ممکن است مجبور شوند نحوه سرمایه گذاری منابع مهندسی را انتخاب کنند.”
کانتر گفت: «فکر میکنم این چیزها را در طول زمان در دورهای مختلف مشاهده خواهید کرد».
یک اثر ثانویه جالب کم بودن رقابت نسبت به انویدیا به این معنی است که برخی از امتیازات برتر برای برخی از وظایف آموزشی نه تنها اکنون نسبت به زمان قبلی بهبود یافته است، بلکه یک رگرسیون است.
به عنوان مثال، در کار ارجمند ImageNet، که در آن یک شبکه عصبی برای اختصاص یک برچسب طبقهبندی کننده به میلیونها تصویر آموزش داده میشود، نتیجه برتر این بار همان نتیجهای بود که در ژوئن رتبه سوم را کسب کرده بود، یک سیستم ساخته شده توسط Nvidia. 19 ثانیه طول کشید تا تمرین شود. این نتیجه در ماه ژوئن به دنبال نتایج حاصل از تراشه “TPU” گوگل بود که تنها 11.5 ثانیه و 14 ثانیه به دست آمد.
در پاسخ به سوالی درباره تکرار ارسال قبلی، انویدیا در ایمیل به ZDNET گفت که تمرکزش این بار بر روی تراشه H100 است نه A100. انویدیا همچنین خاطرنشان کرد که از اولین نتایج A100 در سال 2018 پیشرفت هایی حاصل شده است. در آن دور از معیارهای آموزشی، یک سیستم انویدیا 8 طرفه تقریباً 40 دقیقه طول کشید تا ResNet-50 را آموزش دهد. در نتایج این هفته، آن زمان به کمتر از 30 دقیقه کاهش یافت.
انویدیا همچنین از مزیت سرعت خود در برابر تراشه های هوش مصنوعی Gaudi2 اینتل و پردازنده آتی Sapphire Rapids XEON صحبت کرده است. Nvidia
سالواتوره انویدیا در پاسخ به سوالی درباره کمبود ارسالهای رقابتی و دوام MLPerf، به خبرنگاران گفت: “این یک سوال منصفانه است” و افزود: “ما هر کاری میتوانیم برای تشویق مشارکت انجام میدهیم؛ معیارهای صنعت با مشارکت رشد میکنند.”
سالواتوره گفت: “امید ما این است که همانطور که برخی از راه حل های جدید از سایر راه حل ها به بازار می آیند، آنها بخواهند مزایا و خوبی آن راه حل ها را در معیار استاندارد صنعتی به نمایش بگذارند. ادعاهای عملکرد یکباره خود را ارائه می دهند که تأیید آنها بسیار دشوار است.”
به گفته سالواتوره، یکی از عناصر کلیدی MLPerf، انتشار دقیق تنظیمات و کدهای آزمایشی است تا نتایج آزمون را در بین صدها مورد ارسالی دهها شرکت، واضح و ثابت نگه دارد.
در کنار نمرات معیار آموزشی MLPerf، انتشار روز چهارشنبه توسط MLCommons نتایج تست HPC، معنی، محاسبات علمی و ابررایانهها را نیز ارائه کرد. این ارسالها شامل ترکیبی از سیستمهای Nvidia و شرکا و همچنین ابررایانه Fugaku فوجیتسو بود که تراشههای خود را اجرا میکند.
همچنین: پراکندگی Neural Magic، Nvidia’s Hopper و شبکه Alibaba جزو اولینها در آخرین بنچمارکهای MLPerf AI هستند.
سومین مسابقه به نام TinyML، میزان عملکرد تراشههای کم مصرف و جاسازی شده را در هنگام استنتاج اندازهگیری میکند، بخشی از یادگیری ماشین که در آن یک شبکه عصبی آموزشدیده پیشبینی میکند.
این رقابت، که انویدیا تاکنون در آن شرکت نکرده است، دارای تنوع جالبی از تراشهها و ارسالشدههای فروشندگانی مانند سازنده تراشه Silicon Labs و Qualcomm، غول فناوری اروپایی STMicroelectronics، و استارتآپهای OctoML، Syntiant و GreenWaves Technologies است.
در یکی از تستهای TinyML، یک تست تشخیص تصویر با استفاده از مجموعه دادههای CIFAR و شبکه عصبی ResNet، GreenWaves که مقر آن در گرنوبل، فرانسه است، به دلیل داشتن کمترین تأخیر برای پردازش دادهها و پیشبینی، بهترین امتیاز را کسب کرد. . این شرکت شتاب دهنده هوش مصنوعی Gap9 خود را در ترکیب با یک پردازنده RISC ارائه کرد.
در اظهارات آماده شده، GreenWaves اظهار داشت که Gap9 “مصرف انرژی فوقالعاده پایینی را در شبکههای عصبی با پیچیدگی متوسط مانند سری MobileNet در هر دو وظایف طبقهبندی و شناسایی و همچنین در شبکههای عصبی بازگشتی با دقت ترکیبی پیچیده مانند ما ارائه میکند. حذف کننده صوتی مبتنی بر LSTM“
منبع: https://www.zdnet.com/article/in-latest-benchmark-test-of-ai-its-mostly-nvidia-competing-against-nvidia/#ftag=RSSbaffb68